Processor¶
Introduction¶
In the service interconnection fabric (SIF), each processor node, or simply processor, is a security checkpoint for application control and data flows. Processors facilitate secure application service discovery, enact service connectivity policies with flow-level granularity, and forward encrypted application data between clouds, clusters, and other trusted domains.
The SIF processor is a virtual network appliance available both as an image in Azure, AWS, and GCP and as a package for installation on a Linux machine. As shown in the diagram below, processors are deployed as gateways to trusted domains. Each processor secures a set of workload nodes–physical servers, VMs, Kubernetes worker nodes–in application control (i.e., service discovery) and data planes.
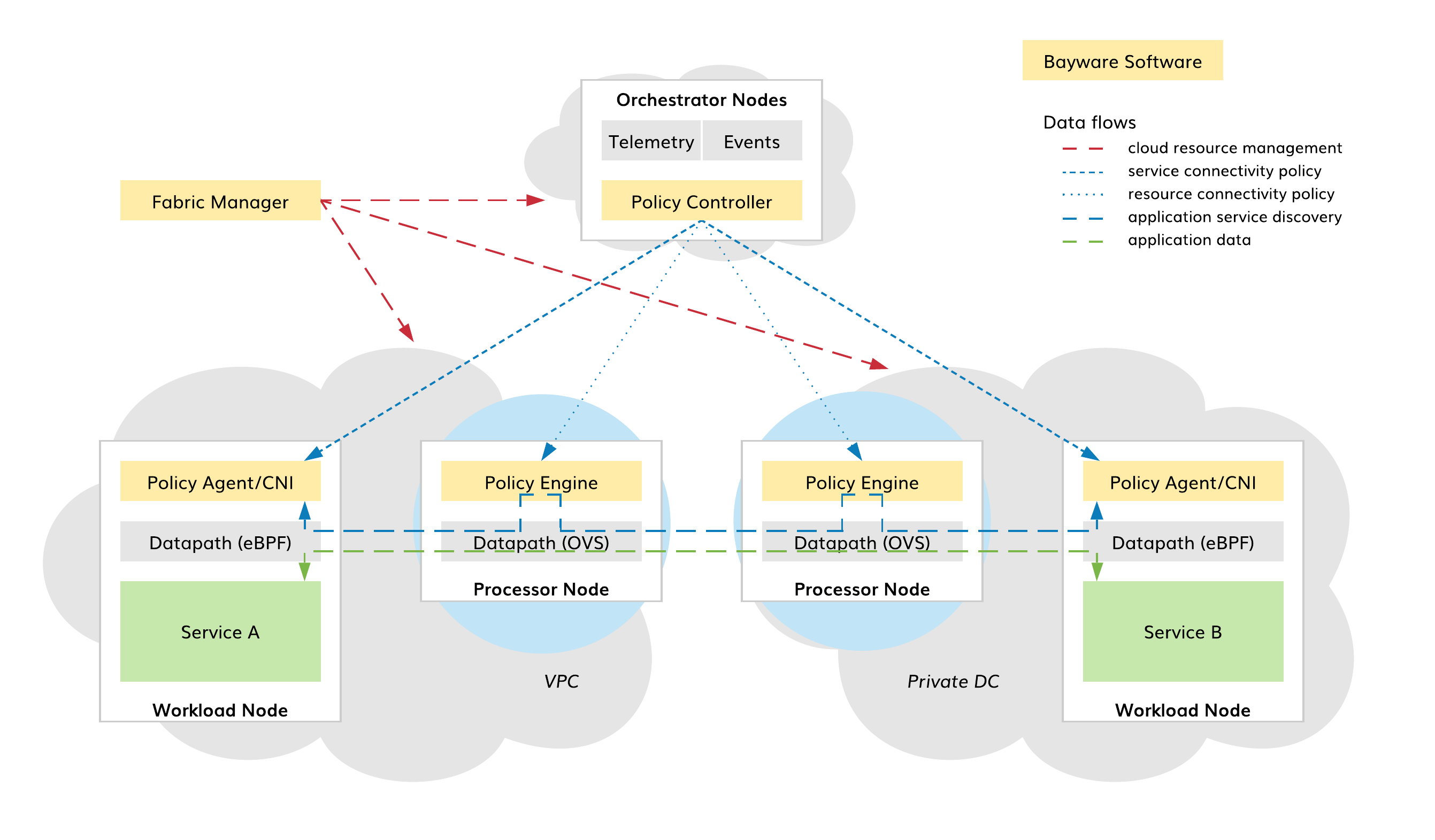
Fig. 111 Processors in SIF
The SIF resource connectivity policy defines processor reachability by workloads and other processors. Each processor enforces resource policy that the fabric orchestrator requests. Policy enforcement starts with automatic processor registration after its installation. The orchestrator checks the processor identity and adds the processor as a new fabric resource. The processor receives link configuration from the orchestrator and automatically sets up secure connections with workloads and other processors. Additionally, the orchestrator assigns labels to the processor and its links to mark the pathways in the fabric for application service discovery requests.
The SIF service connectivity policy defines end-to-end application service reachability. A workload node, hosting an application service instance, sends a service discovery request to an adjacent processor node in order to establish a secure network microsegment in the fabric. After validation, the processor executes the request, configures the microsegment in its datapath using the execution outcome, and forwards the request to other processors or workloads when required. Once the microsegment is established by all the processors en route between the originator and one or multiple responder workloads, service instances on these workloads can immediately start data exchange.
Processors make the SIF a zero-trust communication environment with zero-touch configuration.
Capabilities¶
Overview¶
One or more processors can be assigned to secure a trusted domain, called zone in the SIF policy model. When an SIF administrator adds a workload location to a zone, all the workloads in this location automatically connect with one or several processors serving the zone. If one processor has higher priority than the others, all workloads connect to this processor. Otherwise, connections will be evenly distributed among processors with the same priority.
Note
A processor can be assigned to more than one zone, and in each zone the administrator can select a different priority for the processor.
As shown in the diagram below, each processor plays the following roles:
- SSH jump host,
- IPsec gateway,
- Application policy engine,
- Policy defined datapath.
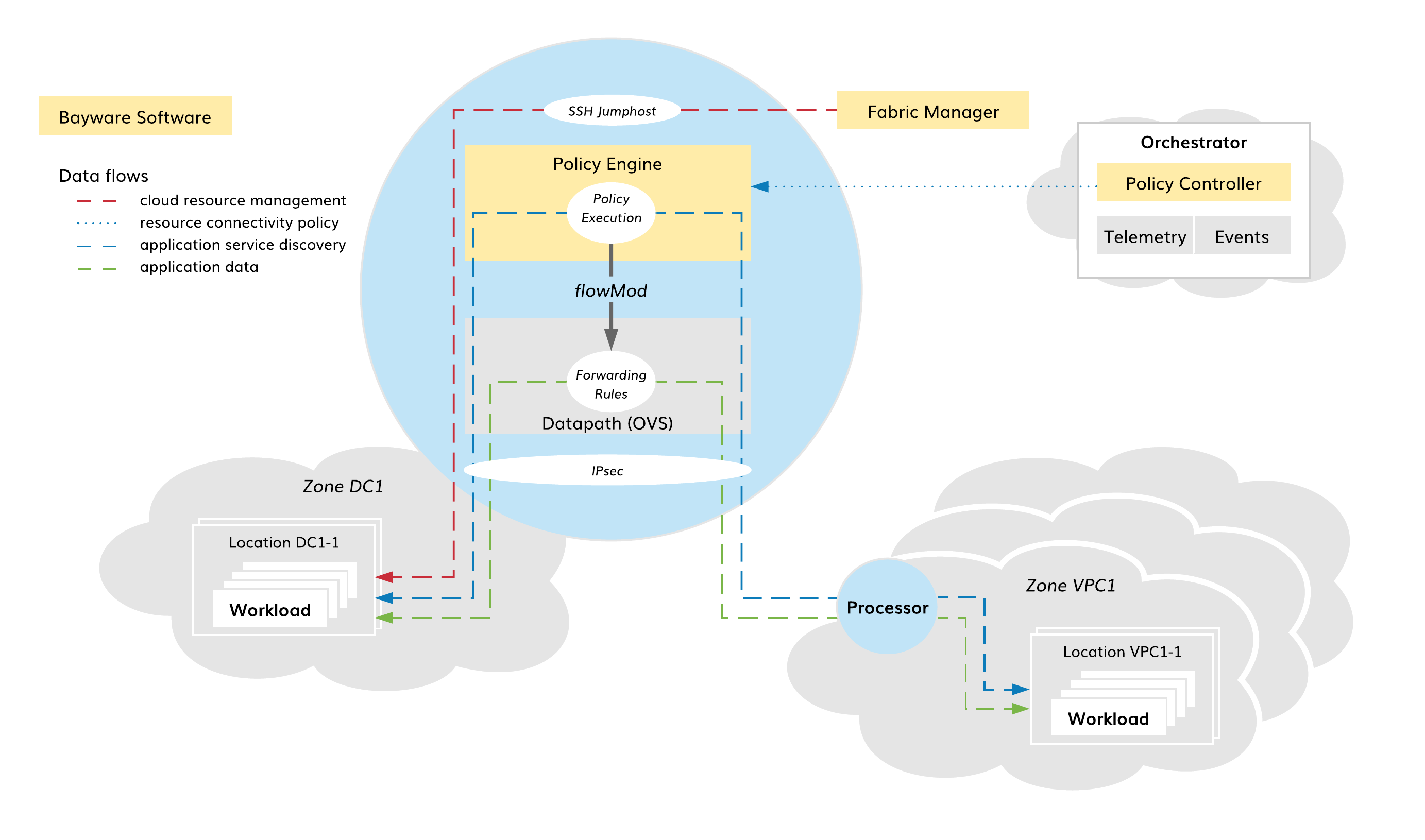
Fig. 112 Processor Capabilities
SSH Jumphost¶
The fabric manager utilizes each processor as a single point of entry into a given security zone. To reach workloads in a given zone, the fabric manager uses one of the zone processors as a Secure Shell (SSH) intermediate hop. This allows the fabric manager to transparently manage workloads in multiple trusted domains without exposing those workloads to public networks, even though they might be in overlapping private IP address spaces.
Using processors as SSH jump hosts enables additional security measurements in the multicloud infrastructure. At the network level, only SSH connections from the fabric manager to zone processors and from zone processors to workloads are permitted. At the SSH level, processors, in this case, perform additional authorization on fabric manager-workload connections.
IPsec Gateway¶
When application data leave the trusted domain, processors automatically encrypt all packets. All processors in a given fabric form a site-to-cloud or cloud-to-cloud VPN, walled off from other fabrics and the outside world. Resource connectivity policy defines a desired VPN topology abstractly as a resource graph with processors playing transit node roles.
As part of resource policy enforcement, the fabric orchestrator imposes link configuration on each processor. Processors use certificate-based mutual authorization to set up secure connections with the prescribed nodes. Then, a standard Linux kernel subsystem performs packet encryption and decryption using hardware acceleration whenever available. Additionally, the fabric manager sets up packet filters to ensure that only IPsec traffic originated or terminated on processors can leave and enter security zones.
Application Policy Engine¶
To be able to communicate with other workloads in the fabric, a workload requests that processors establish one or more secure network microsegments. Processors always work in a default-deny mode. A packet cannot traverse a processor until that processor executes an application connectivity request for the data flow to which the packet belongs.
The connectivity request arrives at the processor as executable code assigned to the flow originator endpoint by the orchestrator. The processor validates the code signature and executes the instructions. The result of code execution may request that the processor: (1) connect the flow endpoint to a given network microsegment and (2) accept data coming to the flow endpoint from a given network microsegment. Using this outcome, the processor sets up local forwarding rules for a period of time specified in the request. Additionally, the application connectivity request may subscribe to requests from other workloads and publish itself to already subscribed workloads.
With this new approach, various connectivity policies can be easily developed or customized. For example, one policy can restrict a microsegment to a subset of trusted domains or even a single domain. Another policy can establish a microsegment with cost-based or load-sharing target selection. Because all these policies are just code, processors will immediately enact them upon workload request across the fabric.
Policy Defined Datapath¶
Each processor includes a standard Linux datapath, running in a default-deny mode. As described above, only workloads can change datapath forwarding behavior. A local policy engine installs rules in the datapath after execution of workload instructions.
Each rule in the datapath processes application data packets in two steps. Firstly, the rule checks whether the packet comes from a flow endpoint already attached to a given microsegment. Secondly, it ensures that the destination node accepts packets from this microsegment. If both true, the datapath forwards the packet to the next hop associated with the destination node.
Such an application-defined datapath enables unprecedented workload mobility plus security with flow-level granularity. The fabric forwarding behavior instantly adapts to new deployments of application service instances as well as application connectivity policy changes.
Internals¶
The processor consists of an application policy engine and a datapath. The policy engine executes application instructions delivered in discovery packets and uses execution outcome to change datapath forwarding behavior.
Policy Engine¶
From a high level, the policy engine functionality breaks down into five modules as presented in the following diagram.
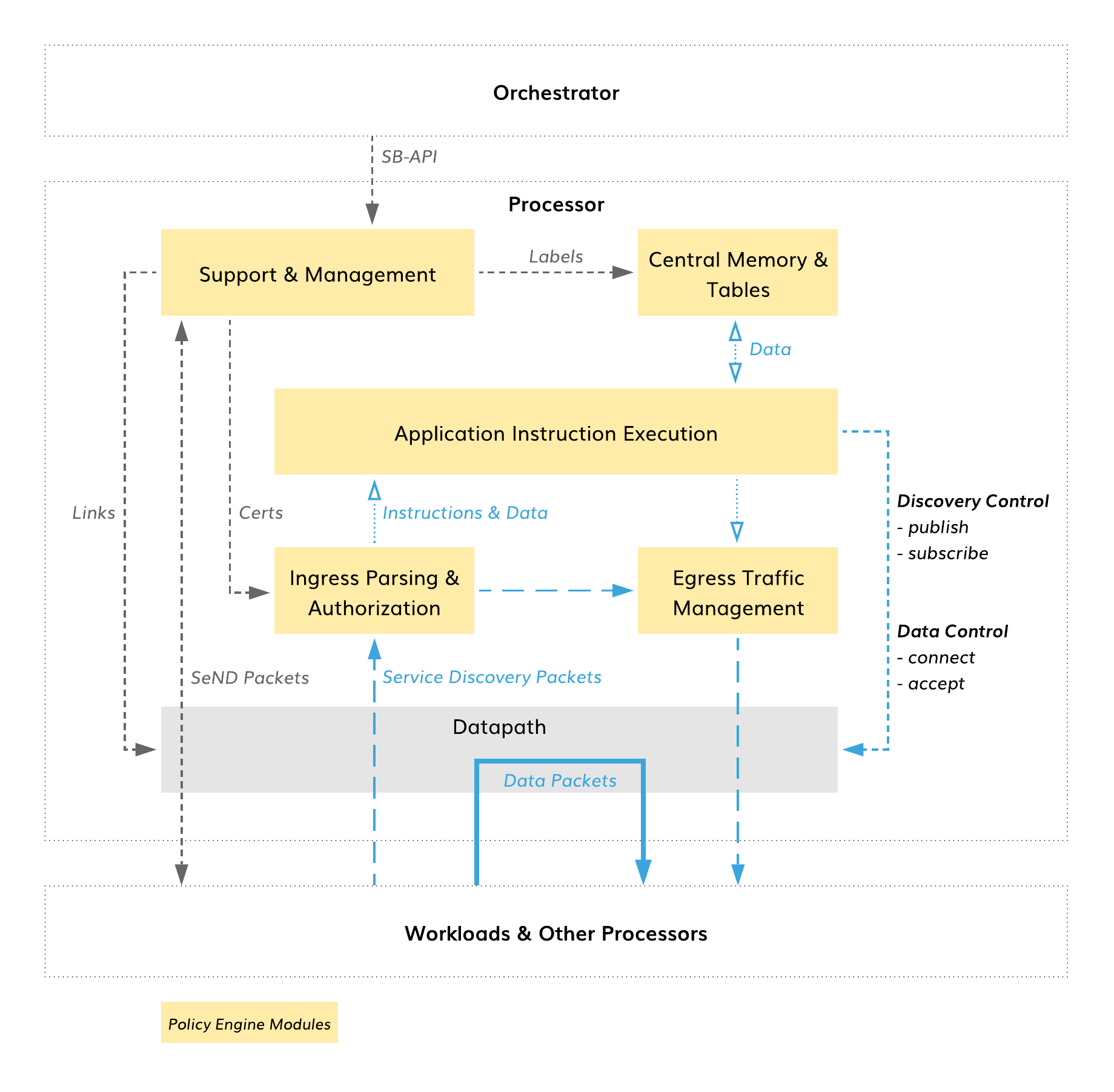
Fig. 113 Policy Engine
Ingress Parsing and Authorization¶
Discovery packets are parsed, classified, rate limited, and processed by security blocks to ensure that only authorized packets proceed to instruction execution.
All discovery-specific information is contained in the IPv6 header. The parser sanity checks the IPv6 header and calls out relevant fields and extensions. An orchestrator ECDSA signature in an IPv6 header extension covers packet authorization information, control data, instructions, and program data. So, security blocks ensure packet legitimacy before instruction execution. In the next step, the classifier performs the necessary lookups in flow and contract tables to initialize an isolated execution environment for the packet instructions. The rate limiter protects security blocks and execution environment from overloading.
Application Instruction Execution¶
A virtual processing unit executes the instructions in the discovery packet using packet program data, stored program data and other shared, processor-level information. Following instruction execution, special logic filters generate control commands for the datapath through a set of allowed actions determined by the security model.
To process instructions, each discovery packet receives a virtual processing unit (PU) fully isolated from the outside world. The PU and instruction set are based on the RISC-V open source ISA. The RV32IAC variant with vector extensions offers support for the base integer instructions, atomic instructions, compressed 16-bit instructions, and vector-processing instructions. A PU uses a virtual 16-bit address space broken into pages. Each page contains address space for a particular control data.
The packet instructions ultimately communicate the result of execution to indicate on which connection(s) the discovery packet should be published and whether to subscribe to incoming discovery packets, connect flow originator to a given network micoregment, or accept data packets coming to the flow endpoint from a given network microsegment.
Central Memory and Tables¶
Each processor contains a set of tables with control data that are central to instruction processing. During execution, the instructions can read and/or write in these tables using the memory pages. The tables contain isolated flow data and shared processor-level information.
Egress Traffic Management¶
The discovery packet content can be modified upon instruction request and sent to workloads or other processors after execution. Egress discovery packets may contain modified program packet data and path pointers in addition to standard IPv6 tweaks, such as hop count.
Support and Management¶
Using Southbound API (SB-API) and Secure Neighbor Discovery (SeND), the policy engine communicates with the fabric orchestrator, workloads, and other processors to support all processor functions including label, certificate and link management.
Datapath¶
The processor uses the standard Open vSwitch (OVS) as a datapath. Only discovery packets can establish packet processing rules for application flows in this datapath. Each rule is ephemeral and its expiry time is derived from an ECDSA signature TTL of the associated discovery packet. A unique authorization and forwarding logic employs two opposite-role rules to process each application packet in the datapath. The datapath executes the logic in a regular, superfast way–by matching packet headers and defining actions for them.
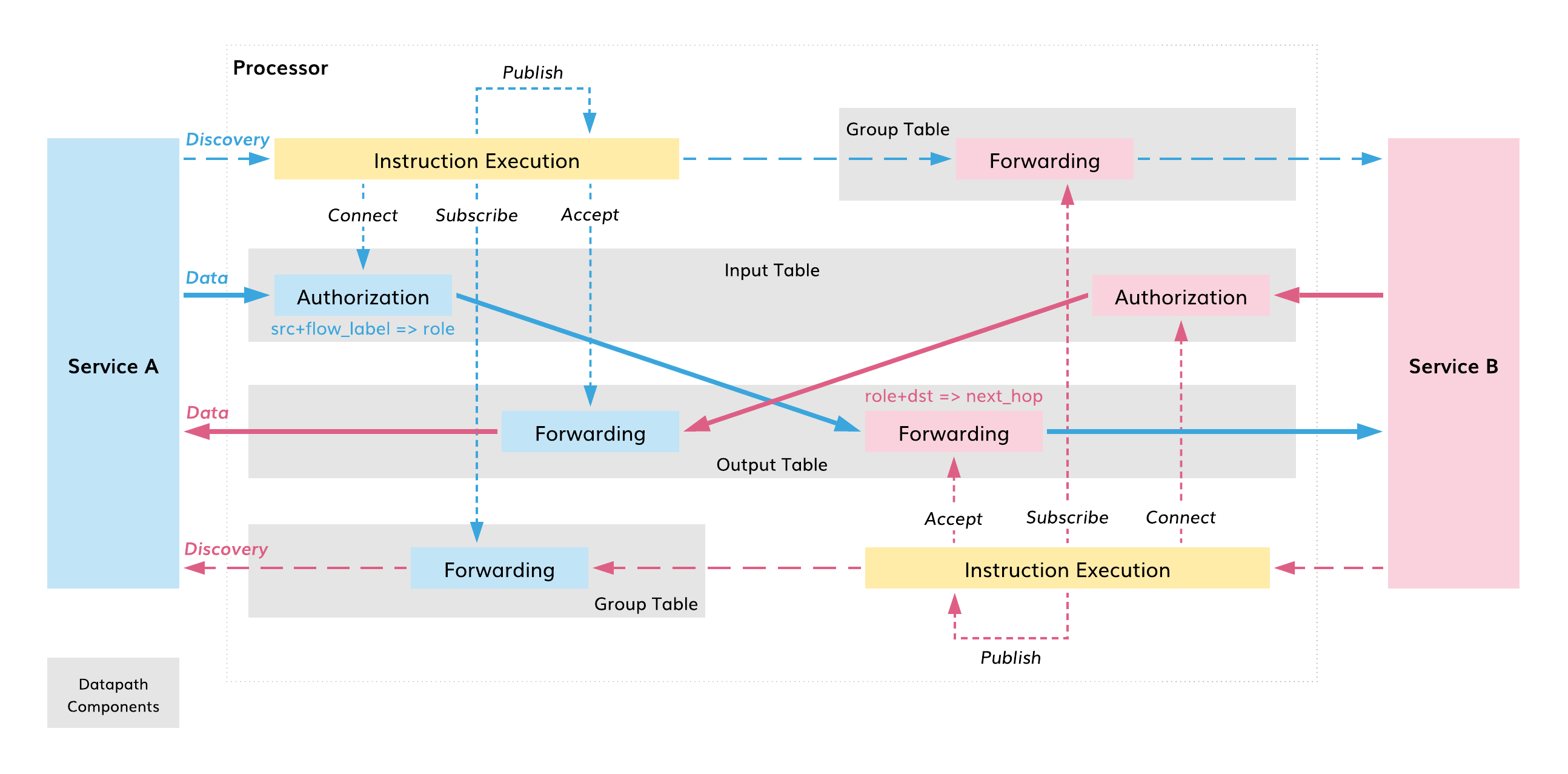
Fig. 114 Processor Datapath
Policy Tables¶
From a high-level, the datapath comprises three types of tables with packet processing rules: Input, Output, and Group. Two global tables, Input and Output, process all unicast data packets. A set of Group tables serves discovery packets and is used instead of the Output table for multicast data packets (not shown on the diagram).
Note
Each network microsegment has always two corresponding Group tables in the datapath.
A discovery packet can instruct the datapath to add records to any or all three tables. The Input table always receives an authorization record. The Group table associated with the discovery packet and the Output table may each conditionally receive a forwarding record.
Required Actions¶
Discovery packet requests are agnostic to the datapath implementation. The instruction execution outcome calls out actions in a highly abstract manner:
- connect the flow originator to a given network microsegment,
- accept data packets destined to the flow originator from a given network microsegment,
- subscribe to discovery packets in a given network microsegment,
- publish the discovery packet on a particular group of ports.
Note
A discovery packet can’t pass any argument while requesting actions connect, accept, and subscribe. Only the action publish() allows the packet to specify egress ports. Upon packet request, special logic filters securely generate rules for the datapath using only controller-signed information from the discovery packet and a vector with egress ports if requested.
The action connect creates an authorization record in the Input table, accept sets up a forwarding record in the Output table, and subscribe installs a forwarding record in the Group table.
Authorized to Forward¶
As data packets arrive, the datapath authorizes them over a set of installed processing rules dropping packets that fail and forwarding the others.
The Input table matches the packet source address and flow label against a set of authorization records in order to associate the packet with a flow endpoint role in a given microsegment. The packet is dropped if the association not found.
In the next step, the Output table matches the packet originator role and destination address against a set of forwarding records. The packet is dropped if the destination is neither found nor accepting data packets with the given role.
Note
In case of a multicast data packet, the datapath sends the packet from the Input table to the Group table associated with the packet originator role. The packet is dropped if the association is not found.
This unique authorize-to-forward approach ensures that the datapath responds to application policy changes in real time and forwards application data packets at line-rate speed.